Data Extraction Process Detail
Extraction of the Sample Data
This graphic illustrates the step-by-step process for extracting the random sample. You can apply it to all reporting sections for when the DVCs deem it permissible to extract a random sample. Select each step to learn about extraction of the sample data.
Appendix H: Data Extraction and Sampling Instructions of the 2025 DV Manual is on the Part C and Part D Data Validation webpage. Scroll down to the 2025 Parts C and D Data Validation file under the Downloads section of the webpage to access the DV Manual.
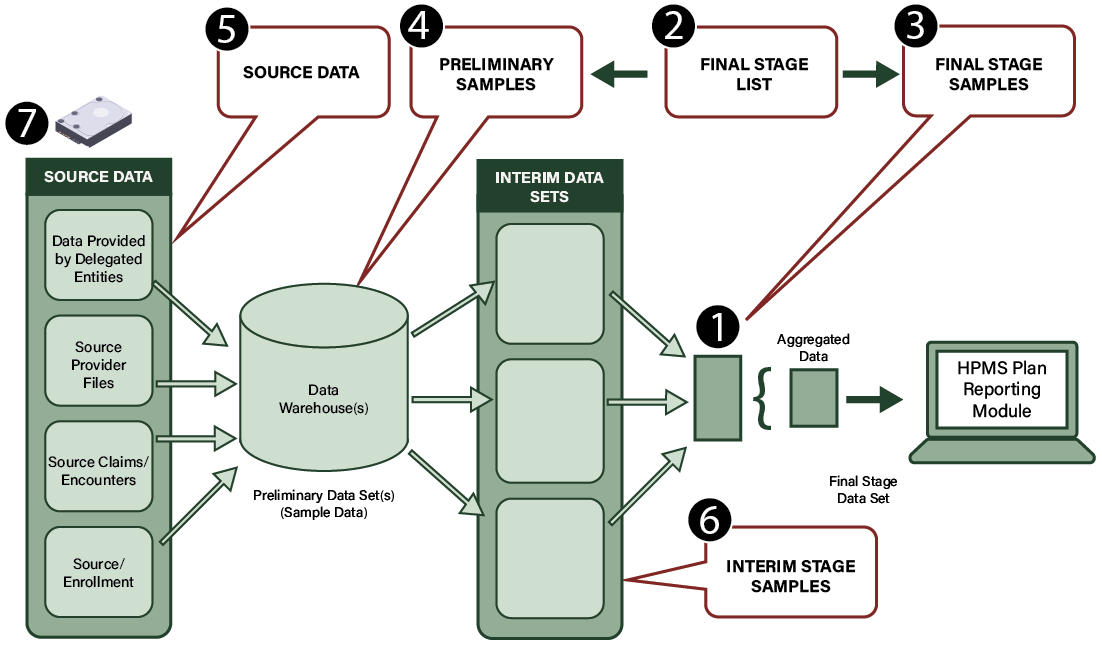
Figure 6: Extraction of the Sample Data
This graphic shows the conceptual framework for data extraction starting with the source data (data given by delegated entities, source provider files, source claims/encounters, and source/enrollment). SOs load the source data to a data warehouse as a preliminary data set(s) (census/sample data) and extract it to create an interim data set. SOs then aggregate the final stage data set and enter it into the Health Plan Management System (HPMS) Plan Reporting Data Validation Module (PRDVM).
Step 1: Identify and Extract Final Stage Data Sets
- Extract the last clean and detailed line-item data file used for the reporting section, before aggregating counts and sums to report the reporting section into HPMS.
Step 2: Draw Random Sample to Create Final Stage List
- Use simple random sampling or more complex sampling approaches to select the distinct sampling units like member IDs and provider IDs, which vary by reporting section, from the final stage data set to create the final stage list.
- In cases with multiple final stage data sets, make sure that the final stage data list is representative of all.
Step 3: Create Final Stage Samples
- Extract all records connected with the identified sampling units in the final stage data list from the final stage data set to create the final stage sample. For example, the grievances final stage sample includes all records and fields in the final stage data set connected with the distinct Case IDs identified in the grievances final stage list.
- In cases with multiple final stage data sets, create multiple final stage samples.
Step 4: Create Preliminary Samples
- The SO should give the DVC files that have data records and data fields referenced in programming code that reside in originating data sources like the internal data warehouse and enrollment system. CMS requires the files to include all records within the reporting period connected with the identified units in the final stage list.
- Refer to the OAI (Appendix E) to find all originating data sources through the information that the SO gave, including source/programming code, data queries, and data dictionaries.
Step 5: Extract Sample Source Data from Underlying Sources for Applicable Reporting Sections
- If officials didn’t extract the source data as part of Step 4, extract sample source data from underlying sources, for example, customer service logs or pharmacy claim files, to make sure that the underlying data were correctly categorized and uploaded or entered into the data warehouse.
Step 6: Create Interim Stage Samples if Applicable
- Extract data sets that have undergone a cleaning process after first entry into a data warehouse and before officials merge or join the data sets with other data sets to create the final stage data set. Apply the same method described in Step 4.
Step 7: Write and Encrypt Data to Secure Storage Device
- Transfer all collected data files to a secure storage device or via a secure web portal.